Pruebas de hipótesis: Resumiendo información acerca de los efectos causales
Fill In Your Name
04 April 2022
- El papel de las pruebas de hipótesis en la inferencia causal
- Temas básicos
de las prueba de hipótesis
- Componentes de una prueba de hipótesis
- Una hipótesis es una afirmación o modelo de una relación entre posibles variables de resultado
- Las estadísticas de pruebas resumen las relaciones entre el tratamiento y las variables de resultado
- El diseño conecta la estadística de prueba y la hipótesis
- El diseño guía la creación de una distribución de estadísticas de prueba hipotéticas
- Planear las distribuciones de aleatoriedad bajo la hipótesis nula
- Los valores \(p\) resumen los planes
- Cómo hacer esto en R: COIN
- Cómo hacer esto en R: RItools
- Cómo hacer esto en R: RI2
- Siguientes temas
- Probando hipótesis nulas débiles
- Rechazando hipótesis
nulas
- Rechazando hipótesis y creando errores
- Tasas de falsos positivos en las pruebas de hipótesis
- Errores de falsos positivos y falsos negativos
- Una sola prueba de una sola hipótesis
- Las decisiones implican errores
- Diagnosticar las tasas de falsos positivos mediante simulación
- Diagnosticar las tasas de falsos positivos mediante simulación
- Diagnosticar falsos positivos mediante simulación
- Diagnosticar las tasas de falsos positivos mediante simulación
- Diagnosticar las tasas de falsos positivos mediante simulación
- Diagnosticar las tasas de falsos positivos mediante simulación
- Tasa de falsos positivos con \(N=60\) y variable de resultado binaria
- Tasa de falsos positivos con \(N=60\) y variable de resultado continua
- Resumen
- Temas avanzados
- Probar muchas hipótesis
- ¿Cuándo podríamos probar muchas hipótesis?
- Tasas de falsos positivos en las pruebas de hipótesis múltiples
- Descubrimientos con pruebas múltiples
- Dos tasas de error principales a controlar cuando se prueban muchas hipótesis
- Preguntas con variables de resultado múltiples
- Pruebas de hipótesis múltiples: Variables de Resultado Múltiples
- Podemos
detectar un efecto en la variable de resultado
Y1? - ¿En cuál de las cinco variables de resultado podemos detectar un efecto?
- ¿Podemos detectar un efecto en “cualquiera” de las cinco variables de resultado?
- Comparación de enfoques I
- Comparación de enfoques II
- La corrección de Holm
- Pruebas de hipótesis múltiples: Brazos de tratamiento múltiples
- Pruebas de hipótesis múltiples: Brazos de tratamiento múltiples
- Pruebas de hipótesis múltiples: Brazos de tratamiento múltiples
- Enfoques para la prueba de hipótesis con múltiples brazos
- Resumen
- Referencias
Planear las distribuciones de aleatoriedad bajo la hipótesis nula
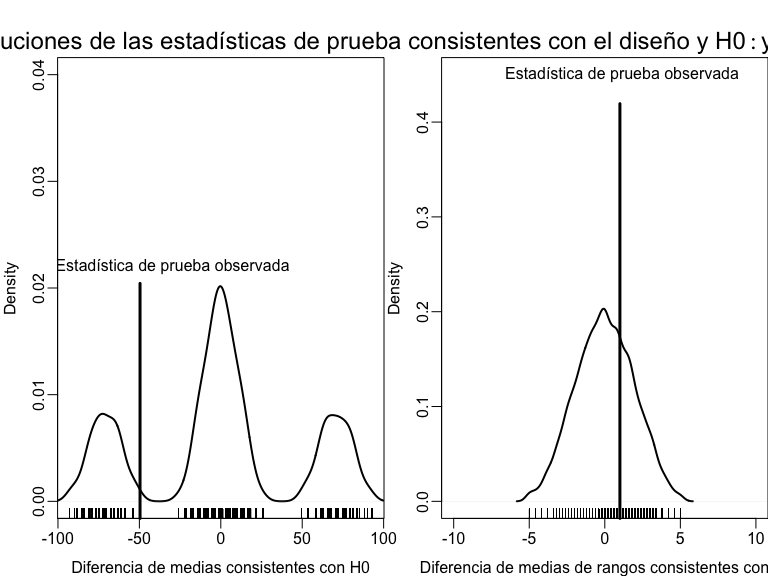
Un ejemplo de uso del diseño del experimento para probar una hipótesis con dos estadísticas de prueba diferentes.
Probando las hipótesis nulas débiles de que no hay efectos promedio
Tanto la variación como la ubicación de \(Y\) cambia con el tratamiento en esta simulación.
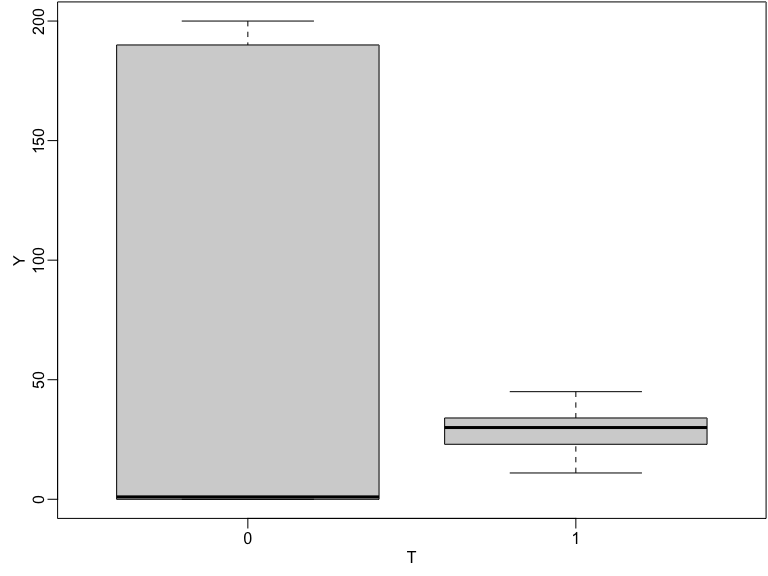
Boxplot de las variables de resultado observados por el estado de tratamiento
Tasas de falsos positivos en las pruebas de hipótesis
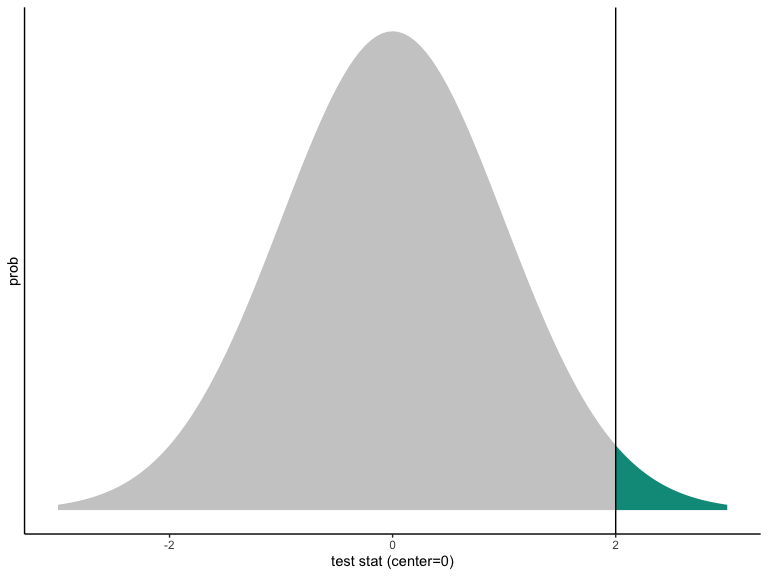
Valor p de una prueba estadística con una distribución normal.
Nótese que:
La curva está centrada en el valor hipotético.
La curva representa el mundo de la hipótesis.
El valor \(p\) es lo raro que sería ver la estadística de prueba observada (o un valor más alejado del valor hipotético) en el mundo de la hipótesis nula.
En la imagen, el valor observado de la estadística de prueba es consistente con la distribución hipotetizada, pero no es súper consistente.
Incluso si \(p < .05\) (o \(p < .001\)), la estadística de prueba observada debe reflejar algún valor de la distribución hipotetizada. Esto significa que siempre se puede cometer un error al rechazar una hipótesis nula.
Diagnosticar las tasas de falsos positivos mediante simulación
Compare las pruebas trazando la proporción de valores p menores que un número determinado. Las pruebas de “inferencia aleatoria” controlan la tasa de falsos positivos (son las pruebas de uso de permutación directa, repitiendo el experimento).
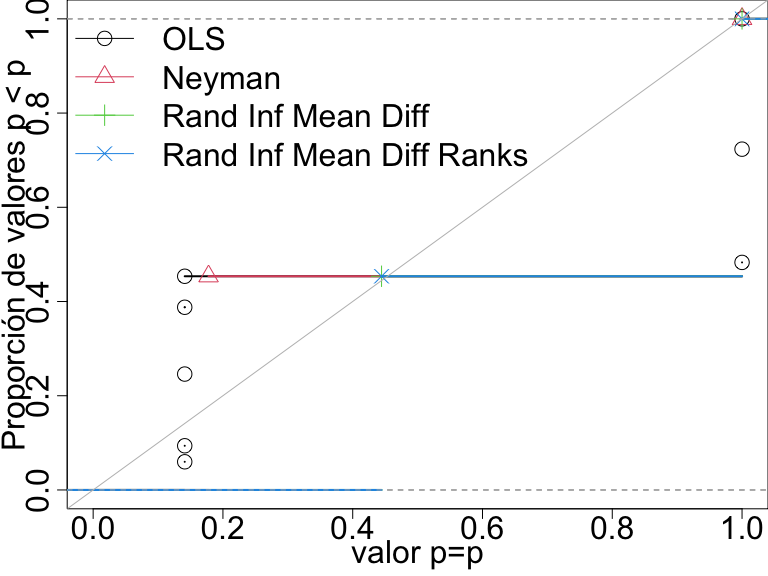
Dist. p-val para 4 pruebas cuando no hay efectos n=10. Cuando la prueba controla su tasa de falsos positivos los puntos caen sobre o por debajo de la línea diagonal.
Tasa de falsos positivos con \(N=60\) y variable de resultado binaria
En este diseño, sólo las pruebas basadas en la inferencia de aleatorización directa controlan la tasa de falsos positivos.
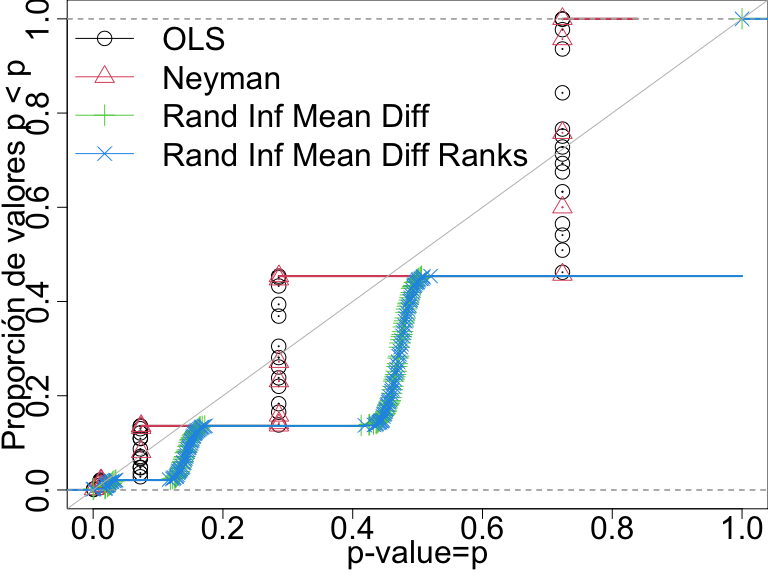
Dist. P-val para 4 pruebas cuando no hay efectos n=60 y una variable de resultado binaria. Una prueba que controla la tasa de falsos positivos debería tener puntos en la línea diagonal o por debajo de ella.
Tasa de falsos positivos con \(N=60\) y variable de resultado continua
Aquí todas las pruebas hacen un buen trabajo al controlar la tasa de falsos positivos.
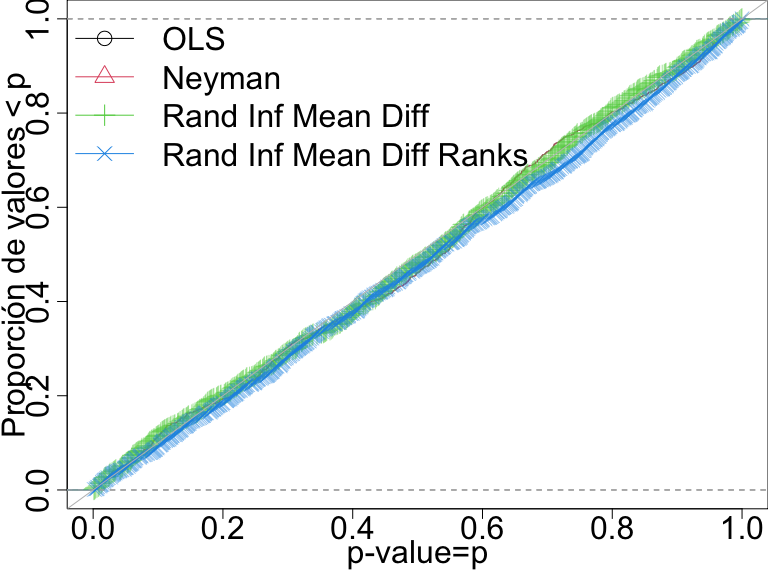
Dist. P-val para 4 pruebas cuando no hay efectos n=60 y una variable de resultado continua. Cuando la prueba que controla la tasa de falsos positivos los puntos caen sobre o debajo de la línea diagonal.