Tests d’hypothèses: résumer les informations sur les effets causaux
Mettre votre nom
04-03-2022
- Le rôle des tests d’hypothèses dans l’inférence causale
- Les bases du test
d’hypothèse
- Ingrédients d’un test d’hypothèse
- Une hypothèse est l’énoncé ou le modèle d’une relation entre des résultats potentiels
- Les statistiques de test résument les relations entre le traitement et les résultats
- La conception lie la statistique de test et l’hypothèse
- La conception guide la création d’une distribution de statistiques de test hypothétiques
- Courbe des distributions de randomisation sous l’hypothèse nulle
- Les \(p\)-valeurs résument les graphiques
- Comment faire cela en R : COIN
- Comment faire cela en R : RItools
- Comment faire cela en R : RI2
- Sujets suivants
- Tester l’hypothèse nulle faible
- Rejeter l’hypothèse nulle
- Rejeter l’hypothèse nulle et faire des erreurs
- Taux de faux positifs dans les tests d’hypothèses
- Erreurs de faux positifs et de faux négatifs
- Un test unique d’une seule hypothèse
- Les décisions impliquent des erreurs
- Diagnostiquer les taux de faux positifs par simulation
- Diagnostiquer les taux de faux positifs par simulation
- Diagnostiquer les taux de faux positifs par simulation
- Diagnostiquer les taux de faux positifs par simulation
- Diagnostiquer les taux de faux positifs par simulation
- Taux de faux positifs avec \(N=60\) et résultat binaire
- Taux de faux positifs avec \(N=60\) et résultat continu
- Sommaire
- Approfondissement
- Tester de nombreuses
hypothèses
- Quand pouvons-nous tester de nombreuses hypothèses ?
- Taux de faux positifs dans les tests d’hypothèses multiples
- Découvertes avec tests multiples
- Deux taux d’erreur principaux à contrôler lors du test de nombreuses hypothèses
- Questions à résultats multiples
- Tests d’hypothèses multiples : résultats multiples
- Pouvons-nous
détecter un effet sur le résultat
Y1? - Pour lequel des cinq résultats pouvons-nous détecter un effet ?
- Pouvons-nous détecter un effet pour un des cinq résultats ?
- Comparaison des approches I
- Comparaison des approches II
- La correction de Holm
- Approches pour tester des hypothèses avec plusieurs bras
- Tests d’hypothèses multiples : bras de traitement multiples
- Tests d’hypothèses multiples : bras de traitement multiples
- Tests d’hypothèses multiples : bras de traitement multiples
- Résumé
- Références
Courbe des distributions de randomisation sous l’hypothèse nulle
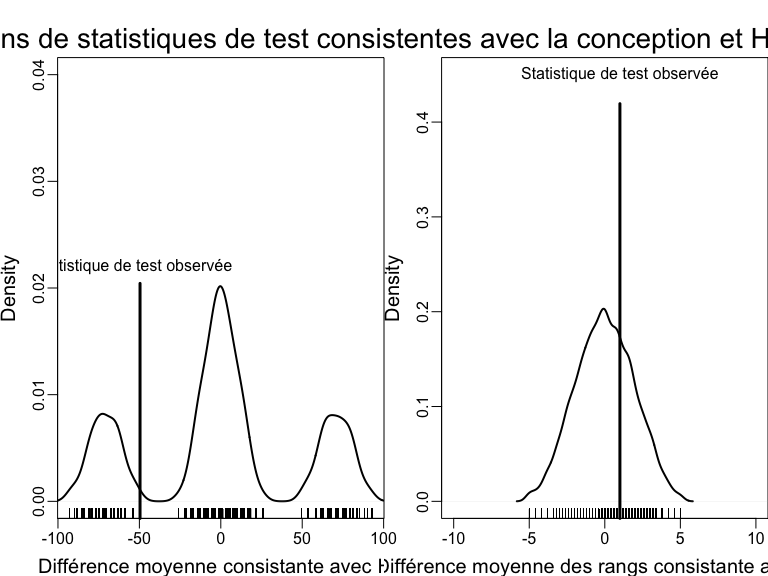
Utiliser la conception d’expérience pour tester une hypothèse avec deux statistiques de test différentes.
Tester l’hypothèse nulle faible d’absence d’effets moyens
La variation et l’emplacement de \(Y\) changent avec le traitement dans cette simulation.
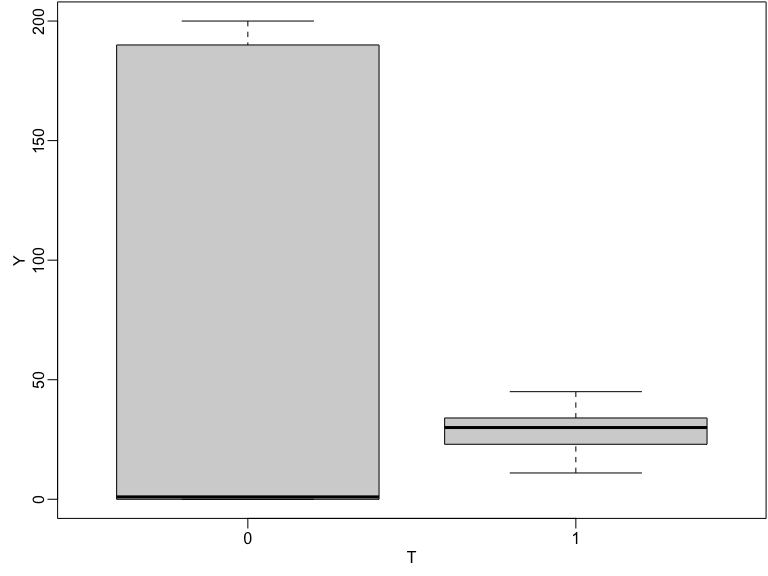
Résultats observés en fonction du statut de traitement
Taux de faux positifs dans les tests d’hypothèses
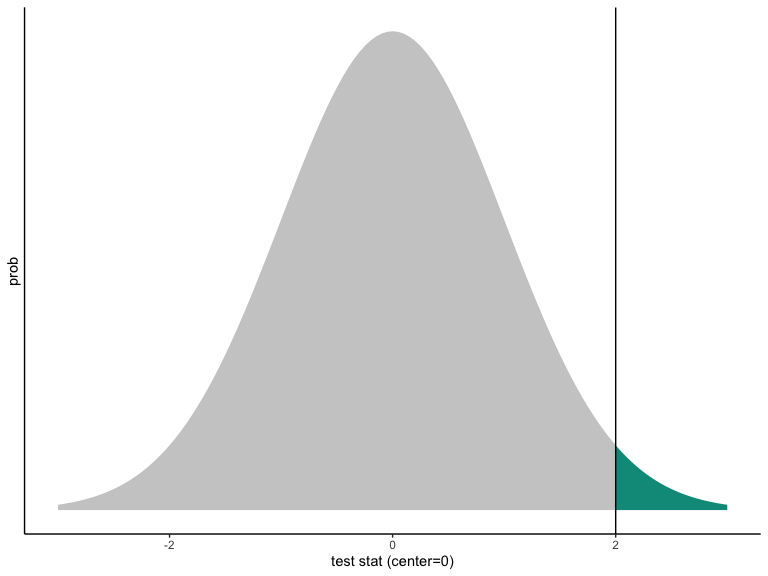
P-valeur unilatérale d’une statistique de test normale.
Attention:
La courbe est centrée sur la valeur hypothétique.
La courbe représente le monde de l’hypothèse.
La \(p\)-valeur décrit à quel point il serait rare de voir la statistique de test observée (ou une valeur plus éloignée de la valeur hypothétique) dans le monde de l’hypothèse nulle.
Sur la figure, la valeur observée de la statistique de test est cohérente avec la distribution hypothétique, mais pas très cohérente.
Même si \(p < 0,05\) (ou \(p < 0,001\)) la statistique de test observée doit refléter en partie la distribution hypothétique. Cela signifie que vous pouvez toujours faire une erreur lorsque vous rejetez une hypothèse nulle.
Diagnostiquer les taux de faux positifs par simulation
Comparez les tests en traçant la proportion de p-valeurs inférieures à un nombre donné. Les tests “d’inférence de randomisation” contrôlent le taux de faux positifs (ce sont les tests avec permutation directe répétant l’expérience).
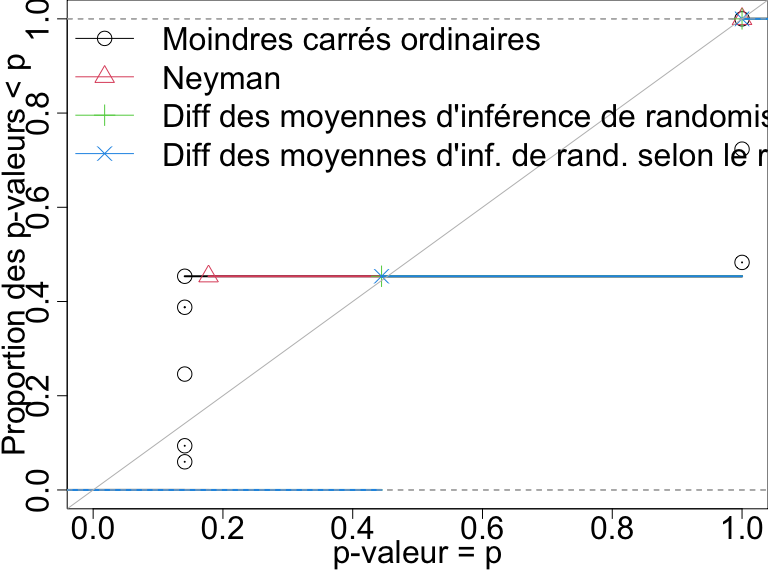
Distributions des p-valeurs quand il n y a aucun effet pour quatre tests avec n=10. Un test qui contrôle son taux de faux positifs doit avoir des points sur ou en dessous de la ligne diagonale.
Taux de faux positifs avec \(N=60\) et résultat binaire
Dans cette conception, seuls les tests basés sur l’inférence de randomisation directe contrôlent le taux de faux positifs.
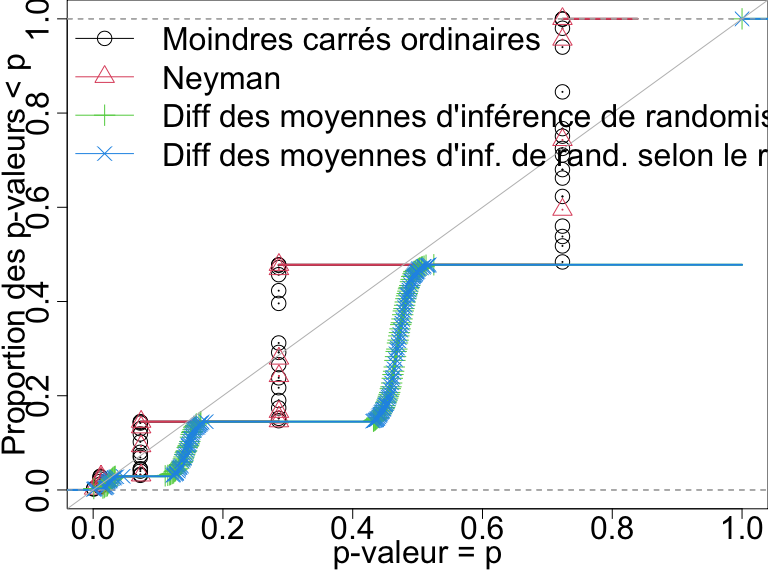
Distributions des p-valeurs quand il n y a aucun effet pour quatre tests avec n=60 et un résultat binaire. Un test qui contrôle son taux de faux positifs doit avoir des points sur ou en dessous de la ligne diagonale.
Taux de faux positifs avec \(N=60\) et résultat continu
Ici, tous les tests contrôlent bien le taux de faux positifs.
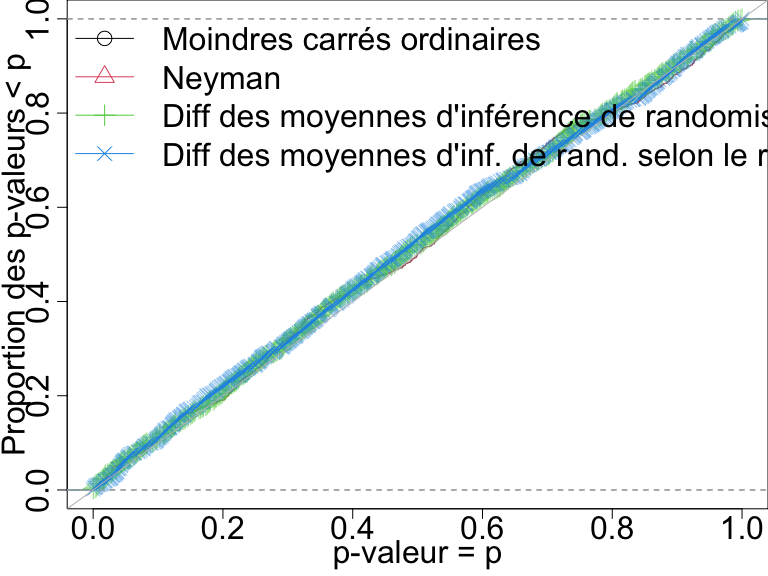
Distributions des p-valeurs quand il n y a aucun effet pour quatre tests avec n=60 et un résultat continu. Un test qui contrôle son taux de faux positifs doit avoir des points sur ou en dessous de la ligne diagonale.
Comment faire cela en R : COIN